Orchestration GPU Cloud — Déployez vos Workloads IA sur n'importe quel Cloud | LayerOps
Orchestration GPU Cloud
Déployez vos Workloads IA sur n'importe quel Cloud
Les ressources GPU sont rares et dispersées entre les fournisseurs. LayerOps fédère les GPUs d'AWS, GCP, OVH, Scaleway et de vos propres serveurs on-premise dans une seule couche d'orchestration. Auto-provisionnez le bon GPU, où qu'il soit disponible — pas de rupture de stock, pas de lock-in.

Fédération GPU Cross-Cloud
Un control plane, tous les GPUs
LayerOps orchestre les ressources GPU de n'importe quel fournisseur cloud et de vos propres serveurs bare-metal via un control plane unique. Taguez vos pools GPU, définissez les priorités de fournisseurs, et laissez la plateforme trouver automatiquement la capacité disponible. Quand un fournisseur est en rupture de stock, les workloads basculent vers le suivant — sans intervention manuelle, sans interruption.
Comparaison de configuration
Déployer un service d'inférence LLM avec accélération GPU. L'approche traditionnelle nécessite des CLI spécifiques au cloud, l'installation manuelle des drivers, et aucun scaling intégré. LayerOps gère tout dans une seule définition de service.
Le voir en Action
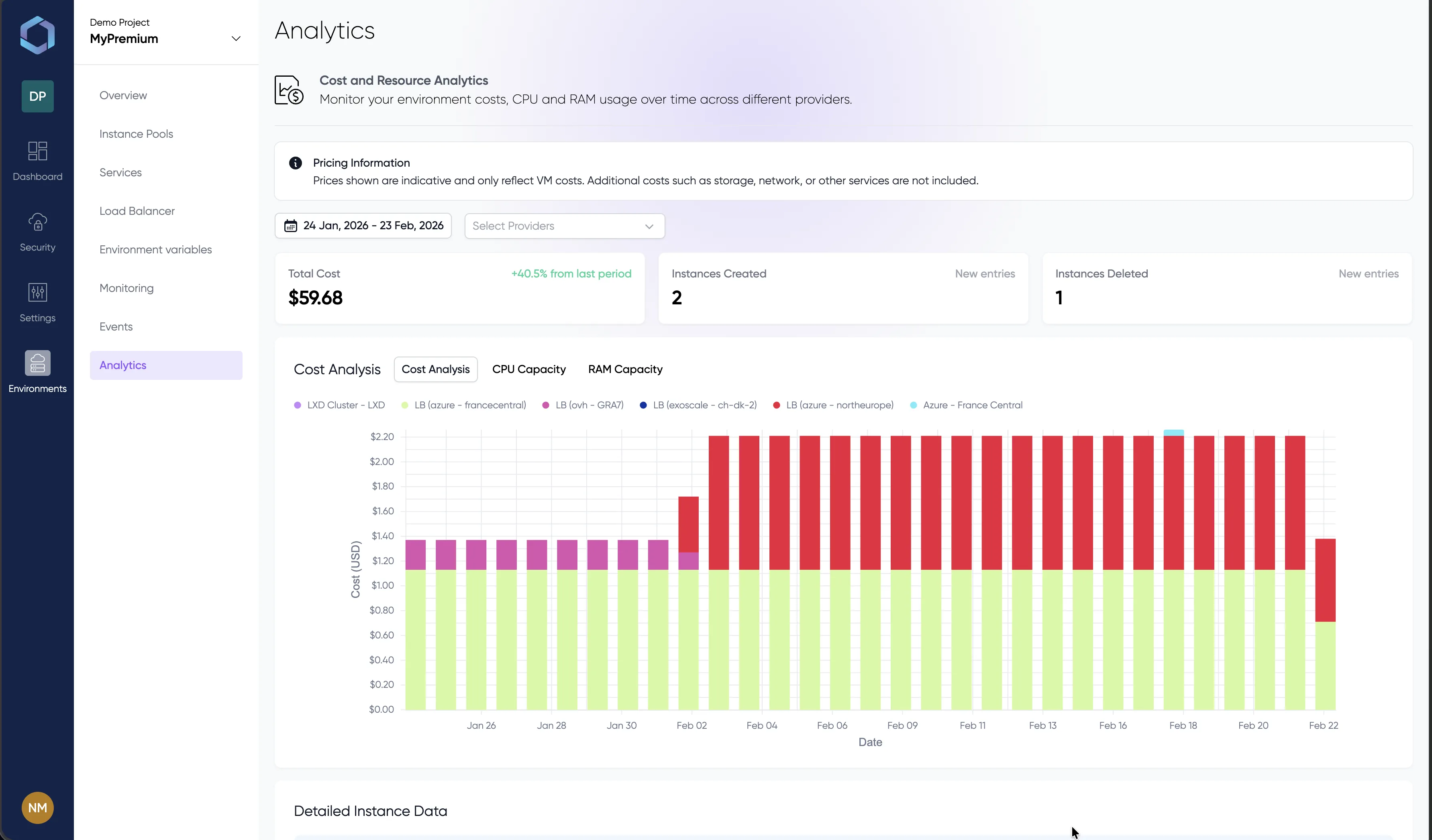
Un aperçu de la console LayerOps
Déployez, supervisez et gérez tous vos conteneurs depuis une seule console.
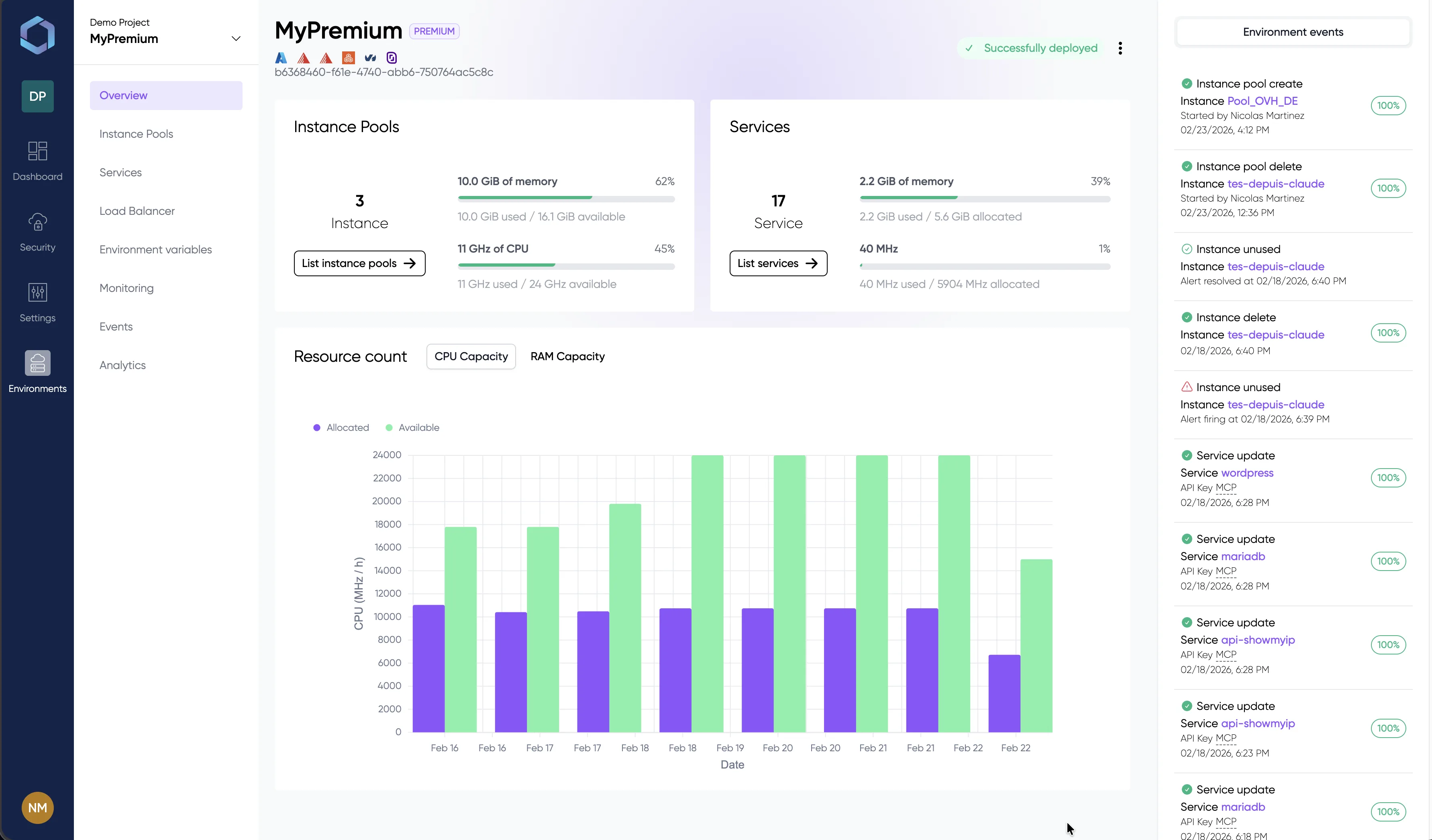
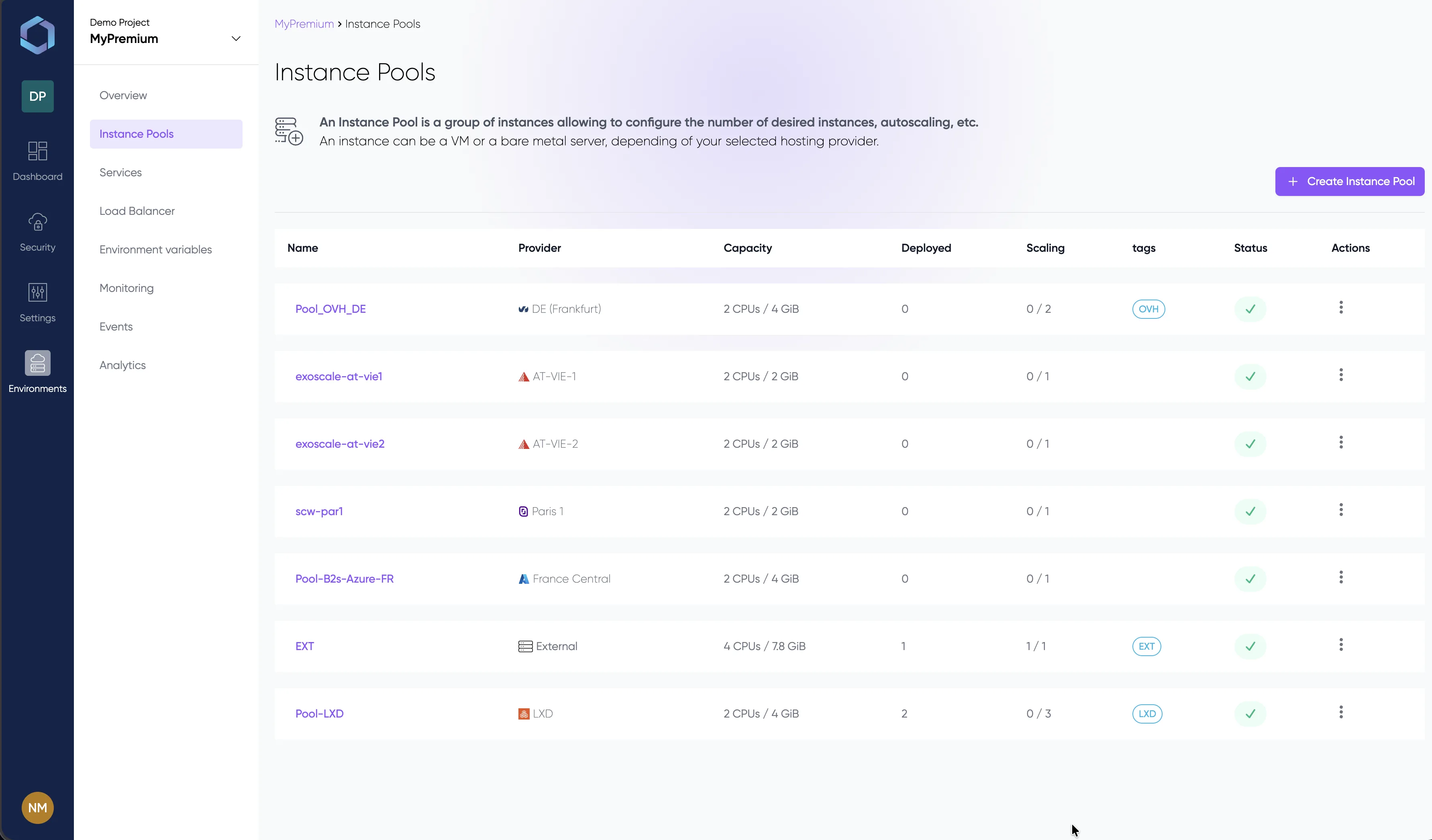
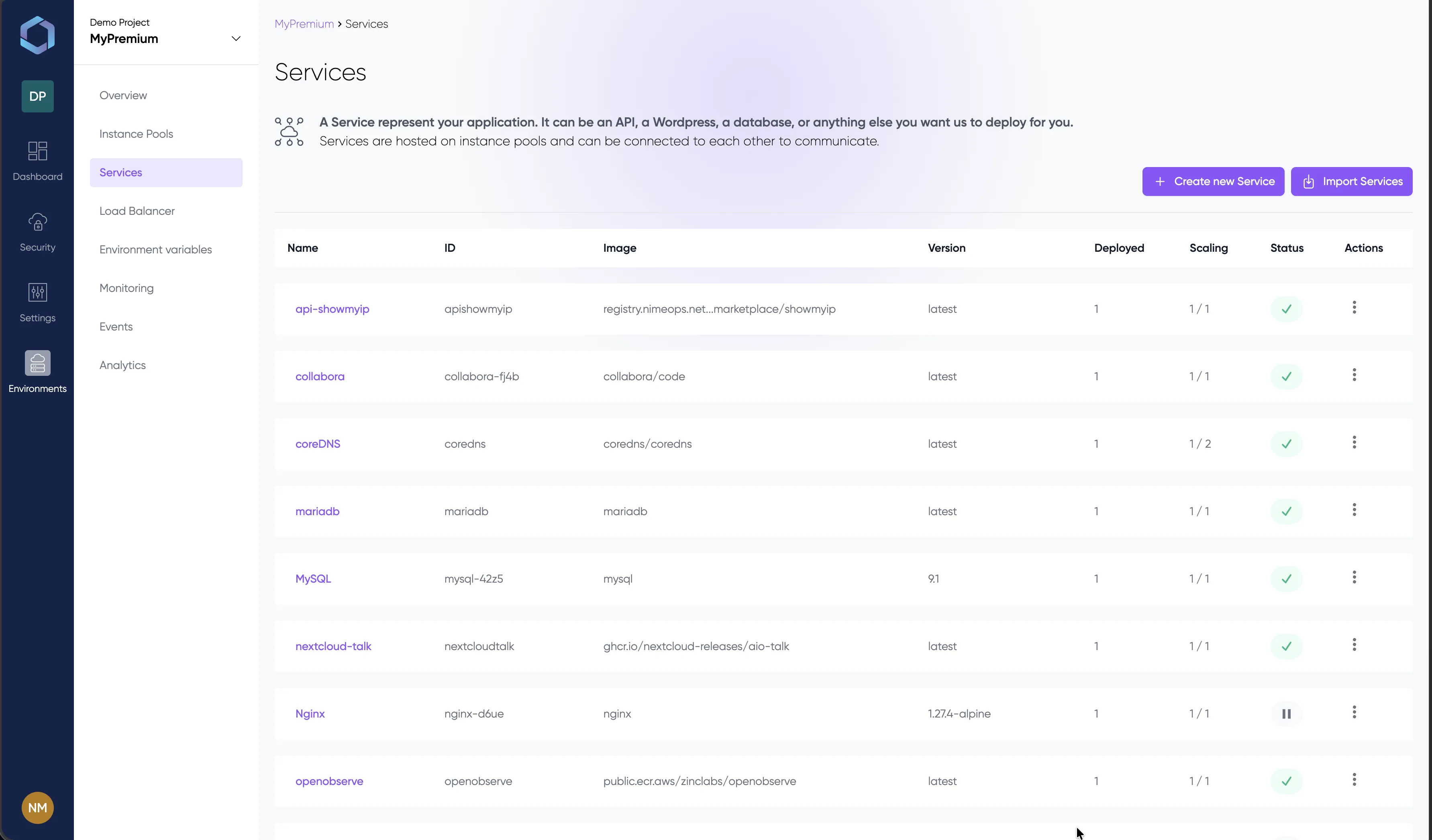
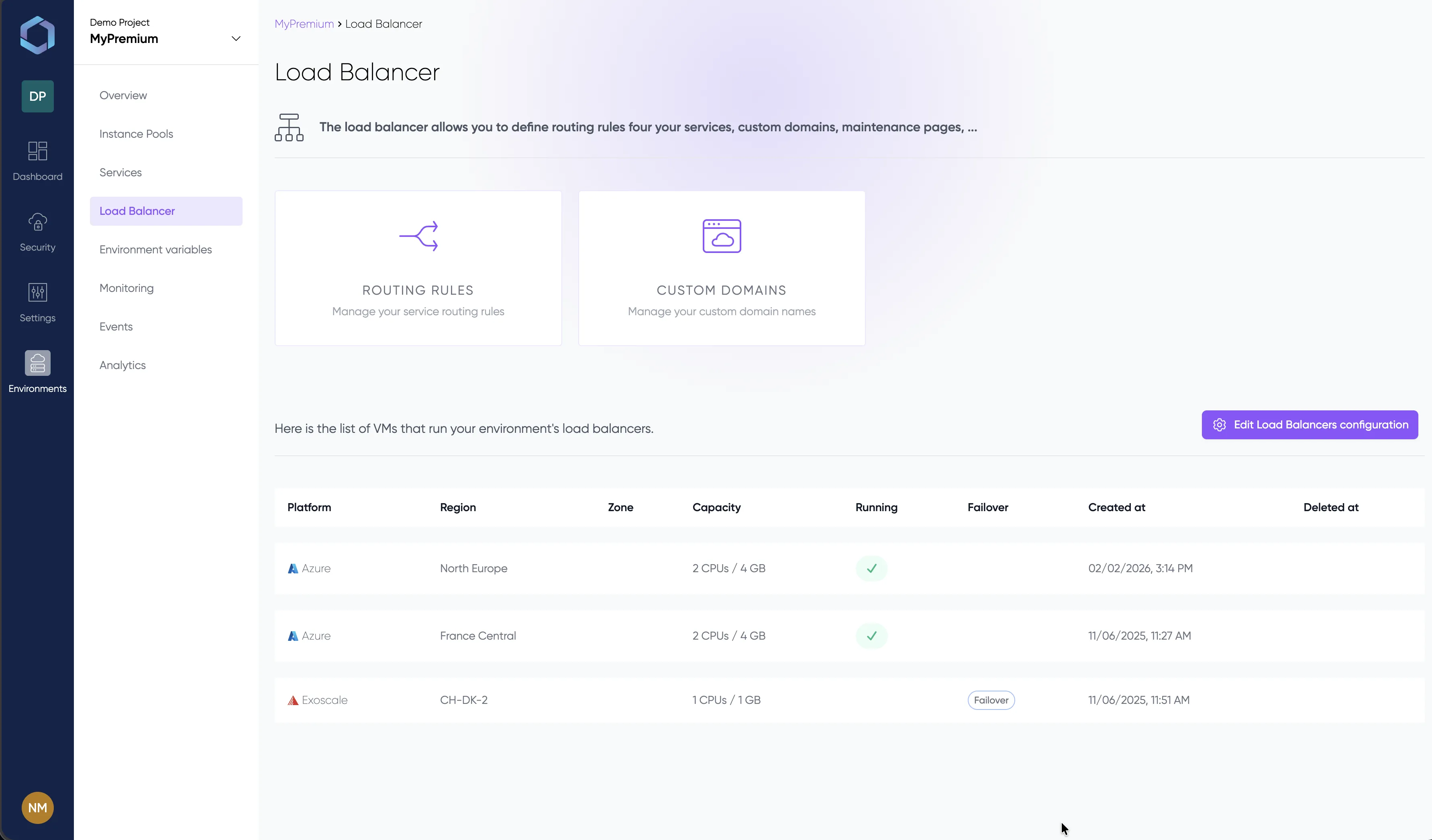
Explorez la console avec des données de démonstration — aucune inscription requise
Pourquoi les équipes choisissent LayerOps pour les workloads GPU
Auto-Provisionnement GPU
LayerOps provisionne automatiquement les instances GPU depuis le fournisseur disponible le moins cher. Plus besoin de chercher de la capacité manuellement ni de naviguer entre les consoles cloud. Taguez vos pools d'instances avec GPU, déployez votre service — la plateforme gère le reste.
GPU Cross-Cloud
Répartissez vos workloads GPU sur AWS, GCP, OVH, Scaleway et votre infrastructure on-premise. Un fournisseur en rupture de stock ? Le trafic bascule automatiquement vers le pool disponible suivant — zéro interruption, zéro intervention manuelle.
IA Souveraine
Déployez vos LLMs sur votre propre infrastructure. Aucun token envoyé vers des APIs externes, aucune donnée quittant votre périmètre. Souveraineté totale sur votre stack IA — conforme aux réglementations défense, santé et finance.
Marketplace Ollama
Déploiement en un clic de Llama 3, Mistral, DeepSeek et d'autres modèles ouverts depuis le marketplace Ollama intégré. Sélectionnez un modèle, choisissez votre pool GPU, déployez — votre LLM privé est en ligne en minutes.
Serveur MCP
Gérez votre infrastructure GPU en langage naturel via le Model Context Protocol. Laissez des agents IA déployer des services, scaler des instances et diagnostiquer votre flotte — directement depuis n'importe quel assistant compatible MCP.
Optimisation des Coûts
Comparaison des coûts GPU en temps réel entre fournisseurs. L'ordonnancement LayerOps place les workloads là où le rapport prix-performance est le meilleur. L'analytique des coûts par environnement vous aide à suivre et optimiser vos dépenses d'infrastructure IA.
Traditionnel vs LayerOps
Fini la galère du provisionnement GPU
Le provisionnement GPU traditionnel implique de gérer des CLI spécifiques à chaque cloud, d'installer les drivers NVIDIA manuellement, de subir les ruptures de stock d'un seul fournisseur, et de payer des ressources inutilisées. LayerOps automatise l'ensemble du workflow — de la découverte GPU au failover cross-cloud — dans une seule plateforme intégrée.


Infrastructure IA Souveraine
Vos modèles, vos données, vos règles
Déployez Llama 3, Mistral, DeepSeek ou n'importe quel LLM ouvert sur vos propres serveurs GPU — on-premise ou dans des clouds souverains. Aucun token envoyé vers les APIs OpenAI ou Anthropic. Vos données d'entraînement, poids de modèle et résultats d'inférence restent dans votre périmètre. Prêt pour la conformité défense, santé, finance et toute industrie régulée.
| Infrastructure GPU DIY | LayerOps | |
|---|---|---|
| InstallationTemps jusqu'au premier déploiement GPU | Moins de 10 minutes | |
| Infrastructure as Code | Intégré, en un clic ou YAML | |
| Gestion des drivers GPU | Entièrement managée | |
| Courbe d'apprentissage | Minimale — conçu pour les développeurs | |
| Gestion GPUOrdonnancement GPU cross-cloud | Natif — tout fournisseur, interface unique | |
| Disponibilité des stocks GPU | Cross-cloud — toujours disponible | |
| Auto-provisionnement GPU | Intégré, basé sur les tags | |
| Intégration GPU on-premise | Natif — mixte cloud + on-premise | |
| IA / LLMDéploiement LLM (Ollama) | Marketplace Ollama en un clic | |
| Catalogue de modèles | Intégré (Llama, Mistral, DeepSeek…) | |
| Souveraineté des données | Garantie — aucun appel API externe | |
| Intégration serveur MCP | Gestion d'infrastructure IA intégrée | |
| OpérationsAnalytique des coûts | Ventilation intégrée par fournisseur | |
| Autoscaling des workloads GPU | Natif, multi-fournisseur |
Explorez les capacités associées
L'orchestration GPU LayerOps s'intègre à la plateforme complète. Déployez sur votre propre infrastructure avec LayerOps On-Premise. Découvrez tous les fournisseurs cloud supportés. Construisez des golden paths pour vos équipes IA avec le Platform Engineering. Réversibilité garantie — exportez à tout moment, zéro lock-in. Déjà sur Kubernetes ? Voir LayerOps vs Kubernetes.
Voyez par vous-même
Explorez la console LayerOps sans créer de compte. Parcourez les environnements, services GPU, dashboards de monitoring et configurations de déploiement — avec des données réalistes.
Prêt à déployer vos workloads IA ?
Provisionnez votre premier service GPU en minutes, pas en jours.