Orquestación GPU en la Nube — Despliegue Cargas de Trabajo IA en Cualquier Nube | LayerOps
Orquestación GPU en la Nube
Despliegue Cargas de Trabajo IA en Cualquier Nube
Los recursos GPU son escasos y están dispersos entre proveedores. LayerOps federa GPUs de AWS, GCP, OVH, Scaleway y sus propios servidores on-premise en una única capa de orquestación. Aprovisione automáticamente la GPU adecuada, donde esté disponible — sin agotamientos de stock, sin dependencia de proveedor.

Federación GPU Cross-Cloud
Un plano de control, todas las GPUs
LayerOps orquesta recursos GPU de cualquier proveedor cloud y sus propios servidores bare-metal a través de un único plano de control. Etiquete sus pools de GPU, defina prioridades de proveedor y deje que la plataforma encuentre automáticamente la capacidad disponible. Cuando un proveedor se queda sin stock, las cargas de trabajo se desplazan al siguiente — sin intervención manual, sin tiempo de inactividad.
Comparación de configuración
Despliegue un servicio de inferencia LLM con aceleración GPU. El enfoque tradicional requiere CLIs específicos del cloud, instalación manual de drivers y no incluye escalado. LayerOps lo gestiona en una única definición de servicio.
Verlo en Acción
Un vistazo a la consola de LayerOps
Despliega, supervisa y gestiona todos tus contenedores desde una única consola.
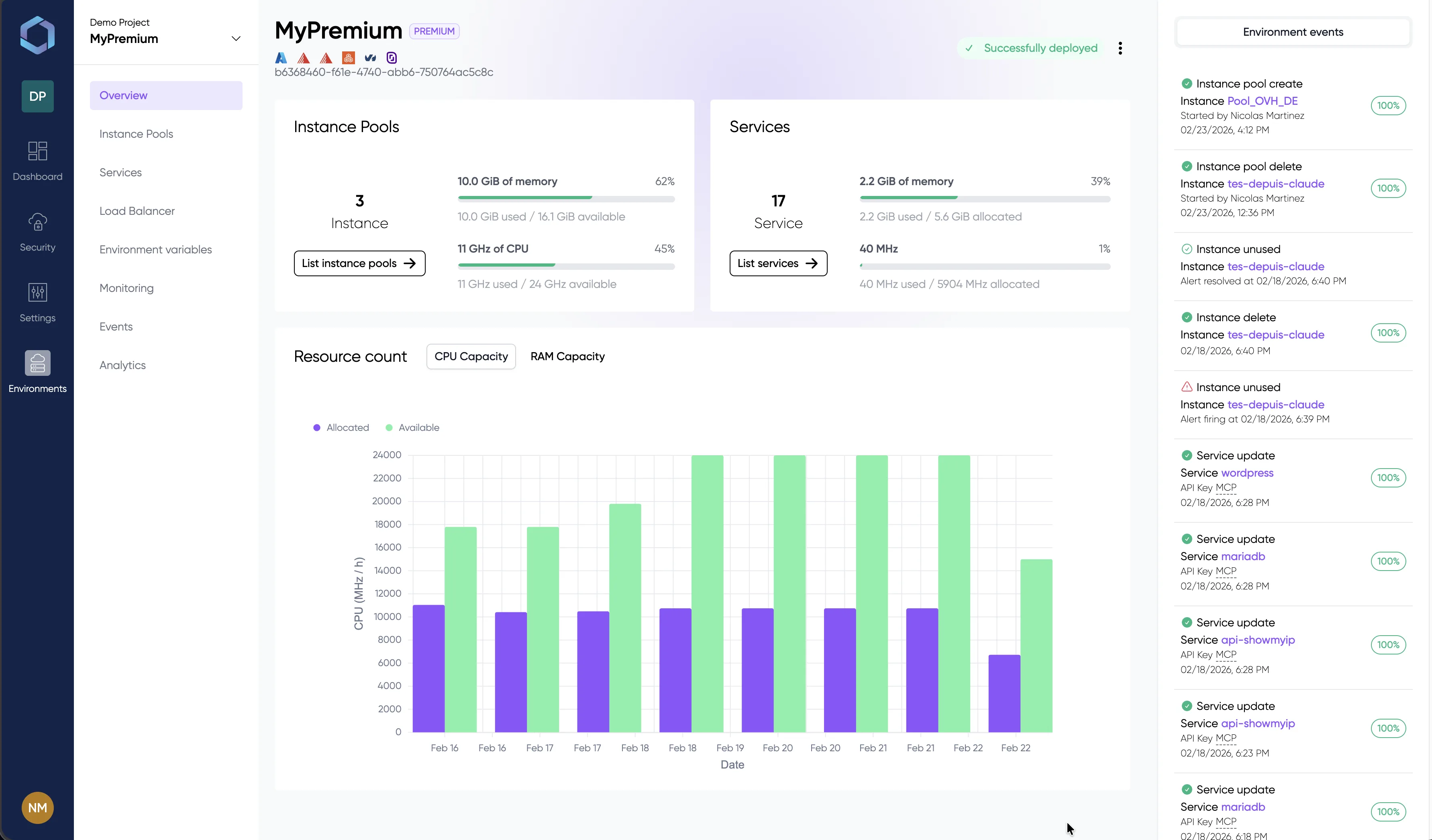
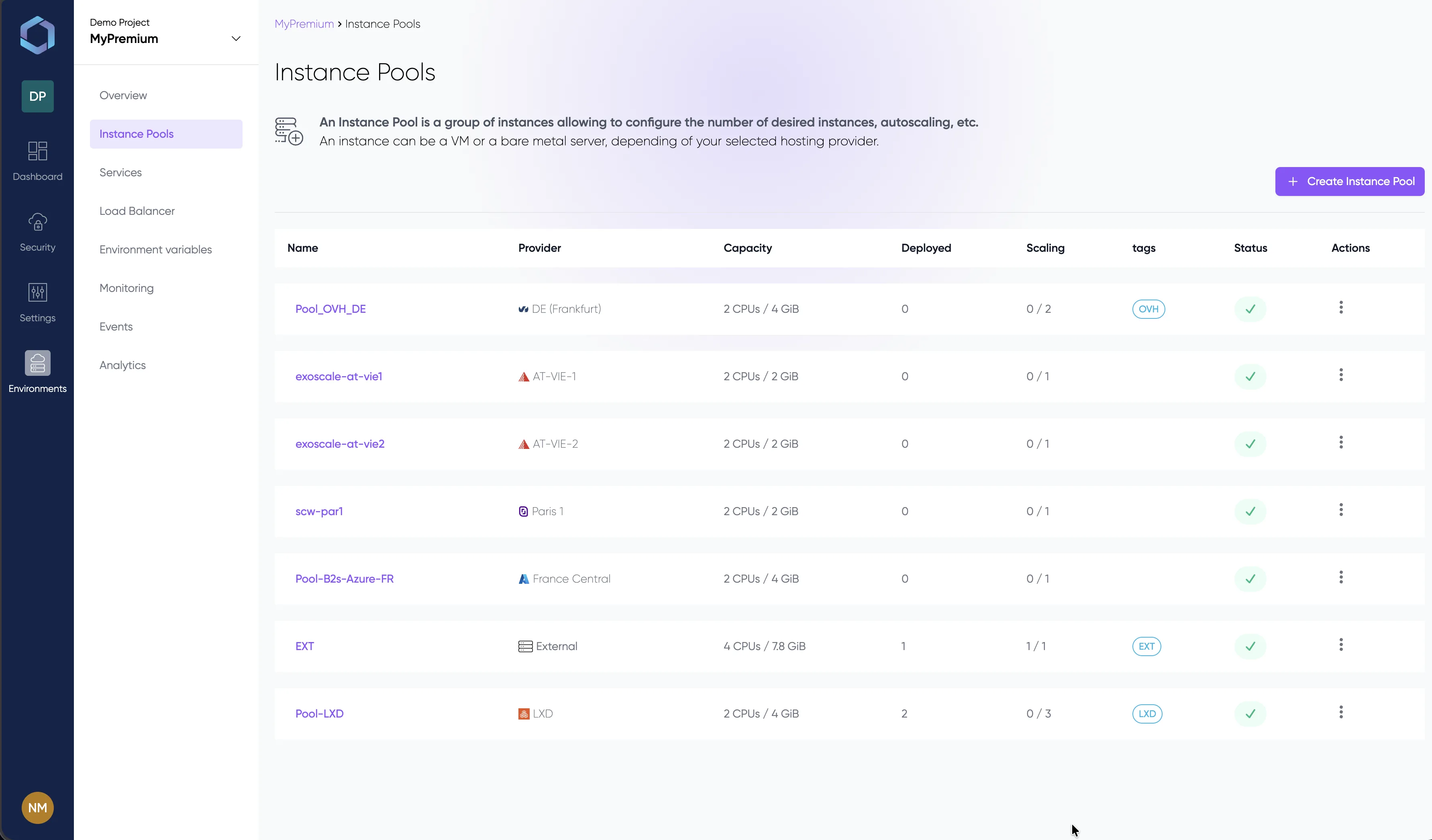
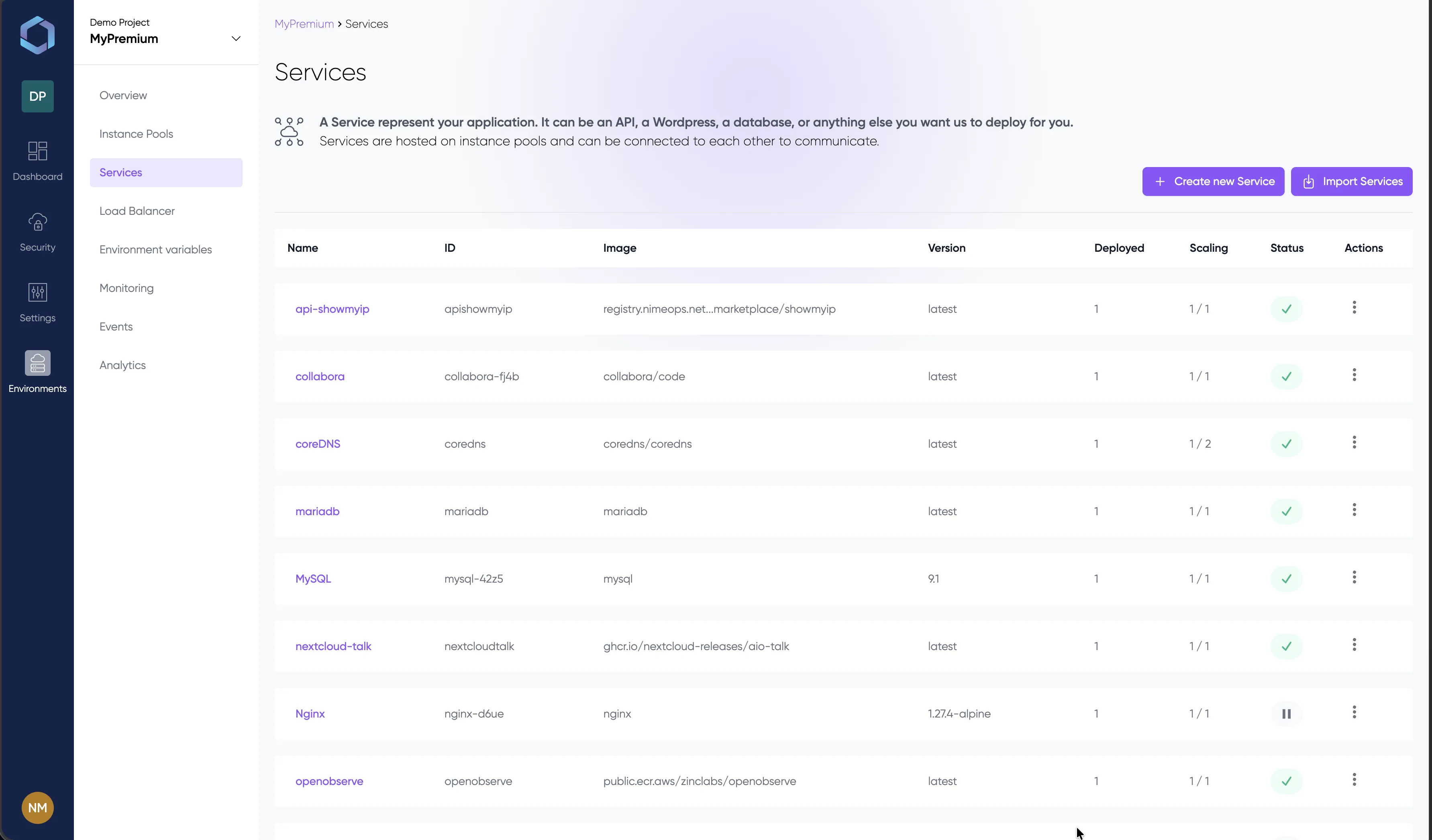
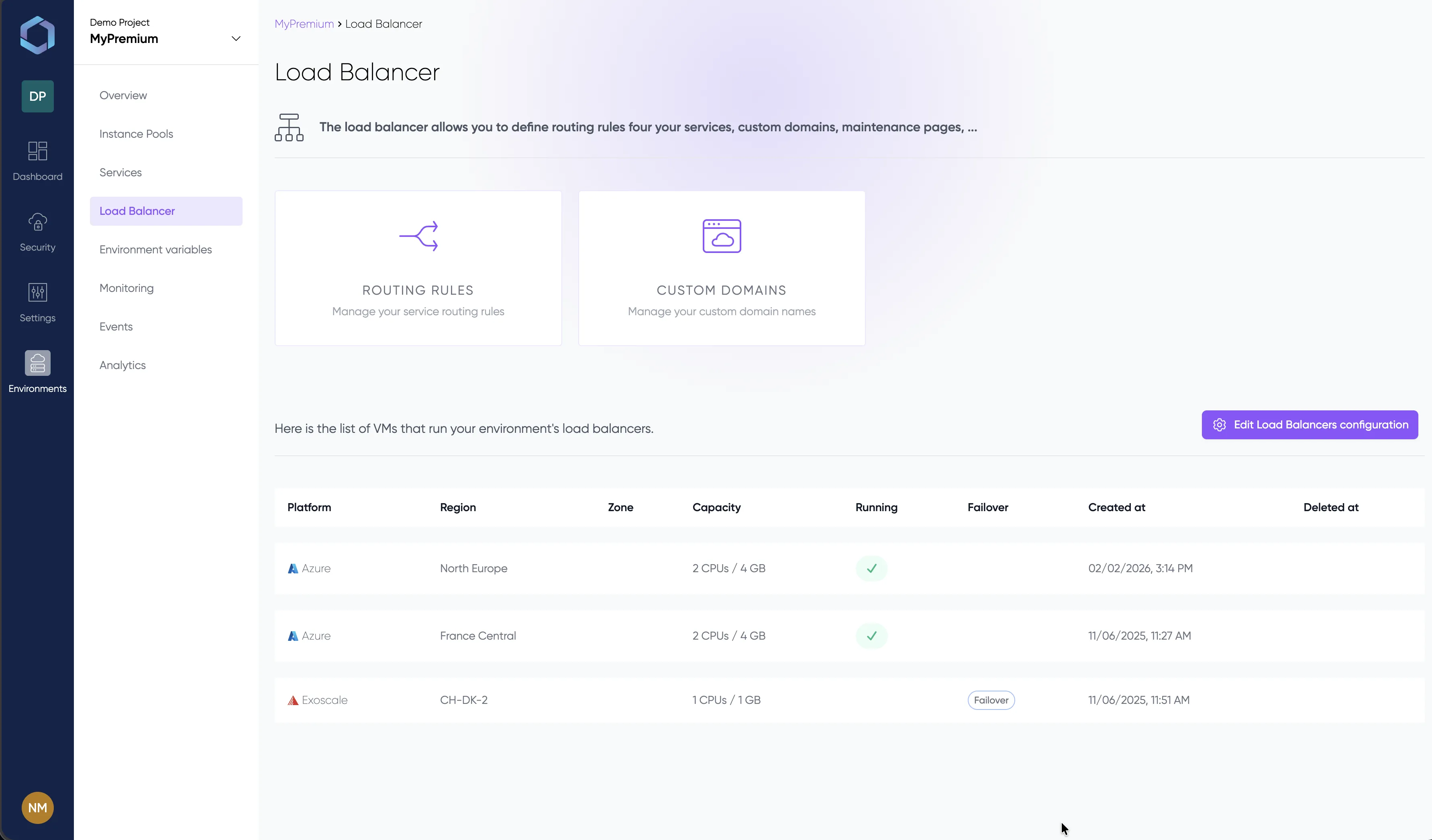
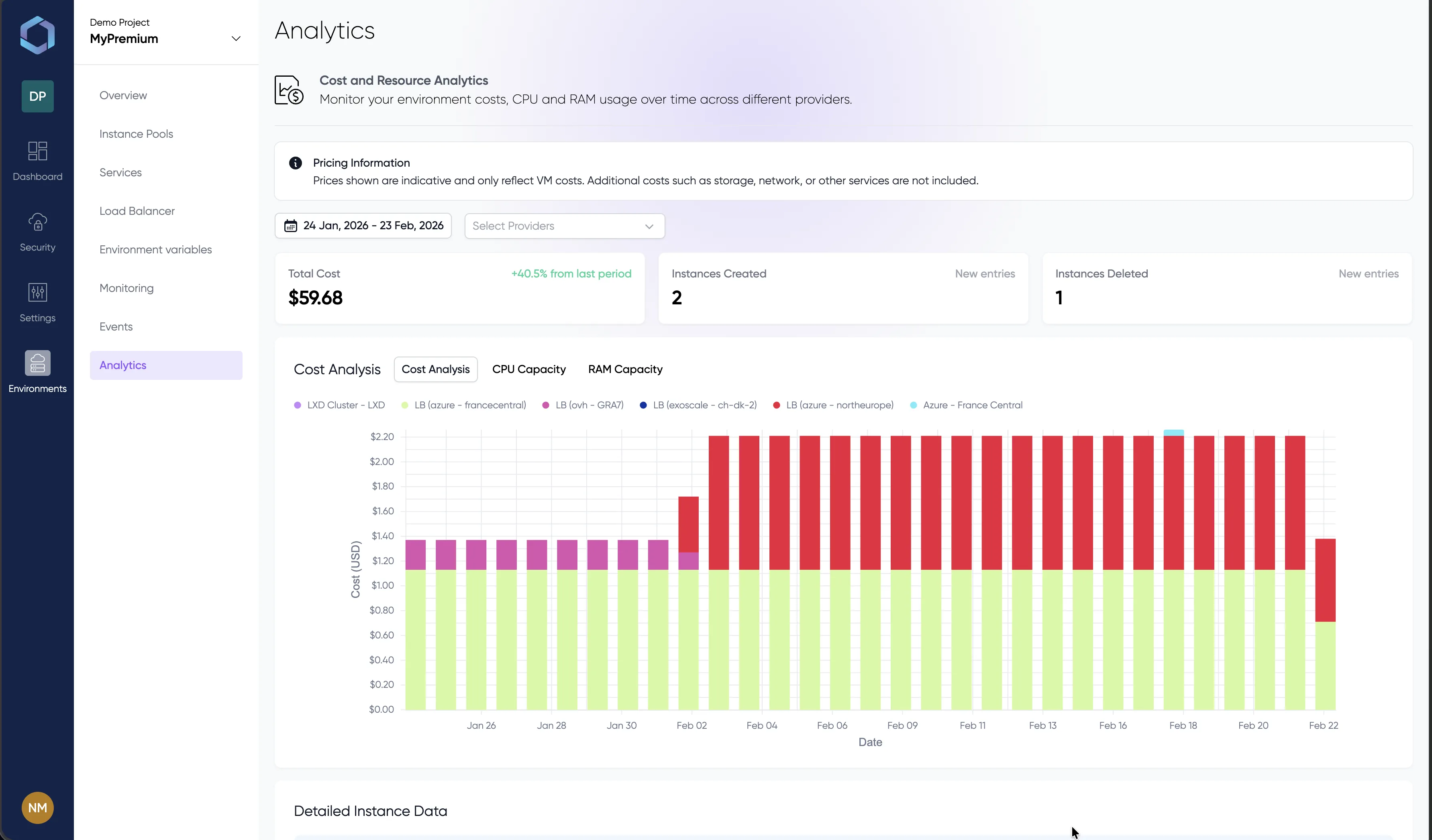
Explora la consola con datos de demostración — sin necesidad de registro
Por qué los equipos eligen LayerOps para cargas de trabajo GPU
Auto-Provisioning de GPU
LayerOps aprovisiona automáticamente instancias GPU del proveedor disponible más económico. Sin búsqueda manual de capacidad, sin saltar entre consolas cloud. Etiquete sus pools de instancias con GPU, despliegue su servicio — la plataforma se encarga del resto.
GPU Cross-Cloud
Distribuya cargas de trabajo GPU entre AWS, GCP, OVH, Scaleway e infraestructura on-premise. ¿El proveedor se queda sin stock? El tráfico se desplaza automáticamente al siguiente pool disponible — cero tiempo de inactividad, cero intervención manual.
IA Soberana
Despliegue LLMs en su propia infraestructura. Sin tokens enviados a APIs externas, sin datos que salgan de su perímetro. Soberanía total sobre su stack de IA — compatible con regulaciones de defensa, sanidad y finanzas.
Ollama Marketplace
Despliegue en un clic de Llama 3, Mistral, DeepSeek y otros modelos abiertos desde el marketplace integrado de Ollama. Seleccione un modelo, elija su pool GPU, despliegue — su LLM privado está listo en minutos.
MCP Server
Gestione su infraestructura GPU mediante lenguaje natural a través del Model Context Protocol. Permita que agentes IA desplieguen servicios, escalen instancias y diagnostiquen su flota — directamente desde cualquier asistente compatible con MCP.
Optimización de Costes
Comparación de costes en tiempo real entre proveedores GPU. La planificación de LayerOps coloca las cargas de trabajo donde la relación precio-rendimiento es óptima. Los análisis de costes por entorno le ayudan a rastrear y optimizar el gasto en infraestructura de IA.
Tradicional vs LayerOps
Termine con el dolor del aprovisionamiento GPU
El aprovisionamiento GPU tradicional implica gestionar CLIs específicos del cloud, instalar drivers NVIDIA manualmente, lidiar con agotamientos de stock de un único proveedor y pagar por recursos inactivos. LayerOps automatiza todo el flujo de trabajo — desde el descubrimiento de GPU hasta el failover cross-cloud — en una única plataforma integrada.


Infraestructura de IA Soberana
Sus modelos, sus datos, sus reglas
Despliegue Llama 3, Mistral, DeepSeek o cualquier LLM abierto en sus propios servidores GPU — on-premise o en nubes soberanas. Sin tokens enviados a APIs de OpenAI o Anthropic. Sus datos de entrenamiento, pesos del modelo y resultados de inferencia permanecen dentro de su perímetro. Listo para el cumplimiento en defensa, sanidad, finanzas y cualquier industria regulada.
| Infraestructura GPU DIY | LayerOps | |
|---|---|---|
| ConfiguraciónTiempo hasta el primer despliegue GPU | Menos de 10 minutos | |
| Infrastructure as Code | Integrado, un clic o YAML | |
| Gestión de drivers GPU | Totalmente gestionado | |
| Curva de aprendizaje | Mínima — diseñado para desarrolladores | |
| Gestión GPUPlanificación GPU cross-cloud | Nativo — cualquier proveedor, panel único | |
| Disponibilidad de stock GPU | Cross-cloud — siempre disponible | |
| Auto-provisioning de GPU | Integrado, basado en etiquetas | |
| Integración GPU on-premise | Nativo — mezcle cloud + on-premise | |
| IA / LLMDespliegue LLM (Ollama) | Ollama marketplace en un clic | |
| Catálogo de modelos | Integrado (Llama, Mistral, DeepSeek…) | |
| Soberanía de datos | Garantizada — sin llamadas a APIs externas | |
| Integración MCP Server | Gestión integrada de infraestructura IA | |
| OperacionesAnálisis de costes | Desglose integrado por proveedor | |
| Autoscaling de cargas GPU | Nativo, cross-provider |
Explore capacidades relacionadas
La orquestación GPU de LayerOps se integra con toda la plataforma. Despliegue en su propia infraestructura con LayerOps On-Premise. Vea todos los proveedores cloud soportados. Construya caminos dorados para sus equipos de IA con Platform Engineering. Reversibilidad garantizada — exporte en cualquier momento, cero dependencia. ¿Ya usa Kubernetes? Vea LayerOps vs Kubernetes.
Véalo en acción
Explore la consola de LayerOps sin crear una cuenta. Navegue por entornos, servicios GPU, dashboards de monitoring y configuraciones de despliegue — todo con datos realistas.
¿Listo para desplegar cargas de trabajo IA?
Aprovisione su primer servicio GPU en minutos, no en días.